Safe and Robust Multi-Agent Reinforcement Learning and Control for Networked CPS
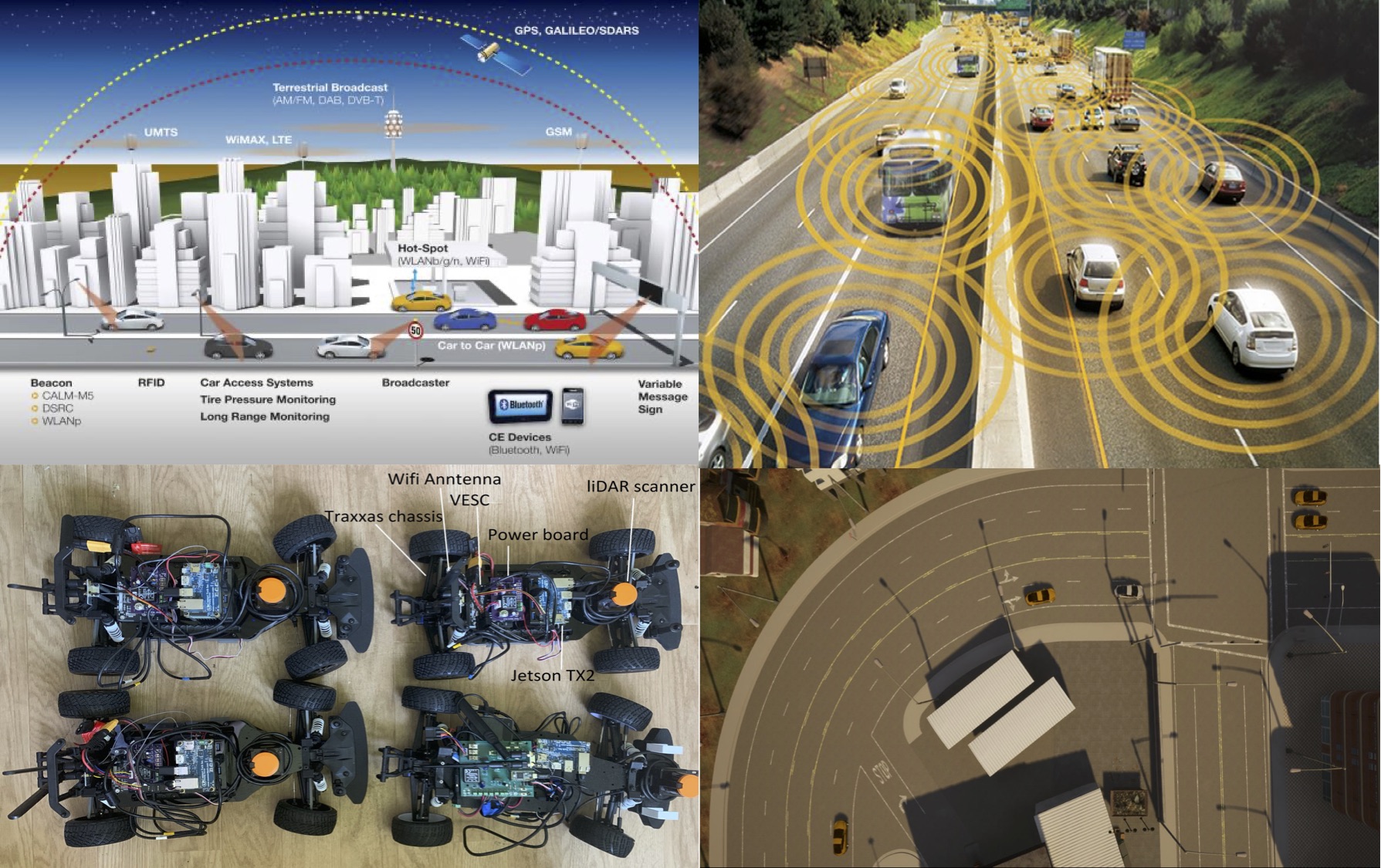
Vehicle-to-vehicle (V2V) and Vehicle-to-Infrastructure (V2I) wireless connectivity is the next frontier in road transportation, which will greatly benefit the safety and reliability of autonomous cars. Information shared among autonomous vehicles provides opportunities to better coordination schemes and also raises novel challenges. In the future, connected autonomous vehicles (CAVs) equipped with both self-driving technology and V2V connectivity, will lead to vastly improved road safety and efficient traffic flow. However, existing literature for connected vehicles or platoons still lacks understanding of the tridirectional relationship among communication, learning, and control of CAVs. Questions such as under what conditions coordination among vehicles can be built, or how to take the best advantage of shared information to improve safety of the connected vehicles and efficiency of the traffic flow remain challenging. Hence, it is critical for future connected autonomous vehicles systems to operate based on integrated learning and control theories, techniques and coordination protocols under complicated environments. This project aims to build fundamental theories and implement experiments for a safe and efficient decision-making process of autonomous vehicles under dynamic and uncertain environment. The benefits of sharing different types of information is analyzed at different scales, from system level efficiency to safety guarantee of each individual autonomous vehicle. Experiments will be implemented with both 1/10th scale racing cars and full-scale autonomous vehicles on Uconn Depot Campus by collaborating with the Connecticut Transportation Safety Research Center.
In Summer 2021, I hosted a virtual research site for two minority scholars of the Young Scholars Senior Summit (YSSS) based on research activities of this award. See more information in Outreach.
"NSF CAREER: Distributionally Robust Learning, Control, and Benefits Analysis of Information Sharing for Connected Autonomous Vehicles" , funded by NSF.
“Robust Control Protocol Synthesis and Safe Learning for Connected Autonomous Vehicles ”, May 2019-June 2020, funded by Uconn Research Excellence Program (REP).
Coordinated CAV Behavior Planning in Challenging Scenarios
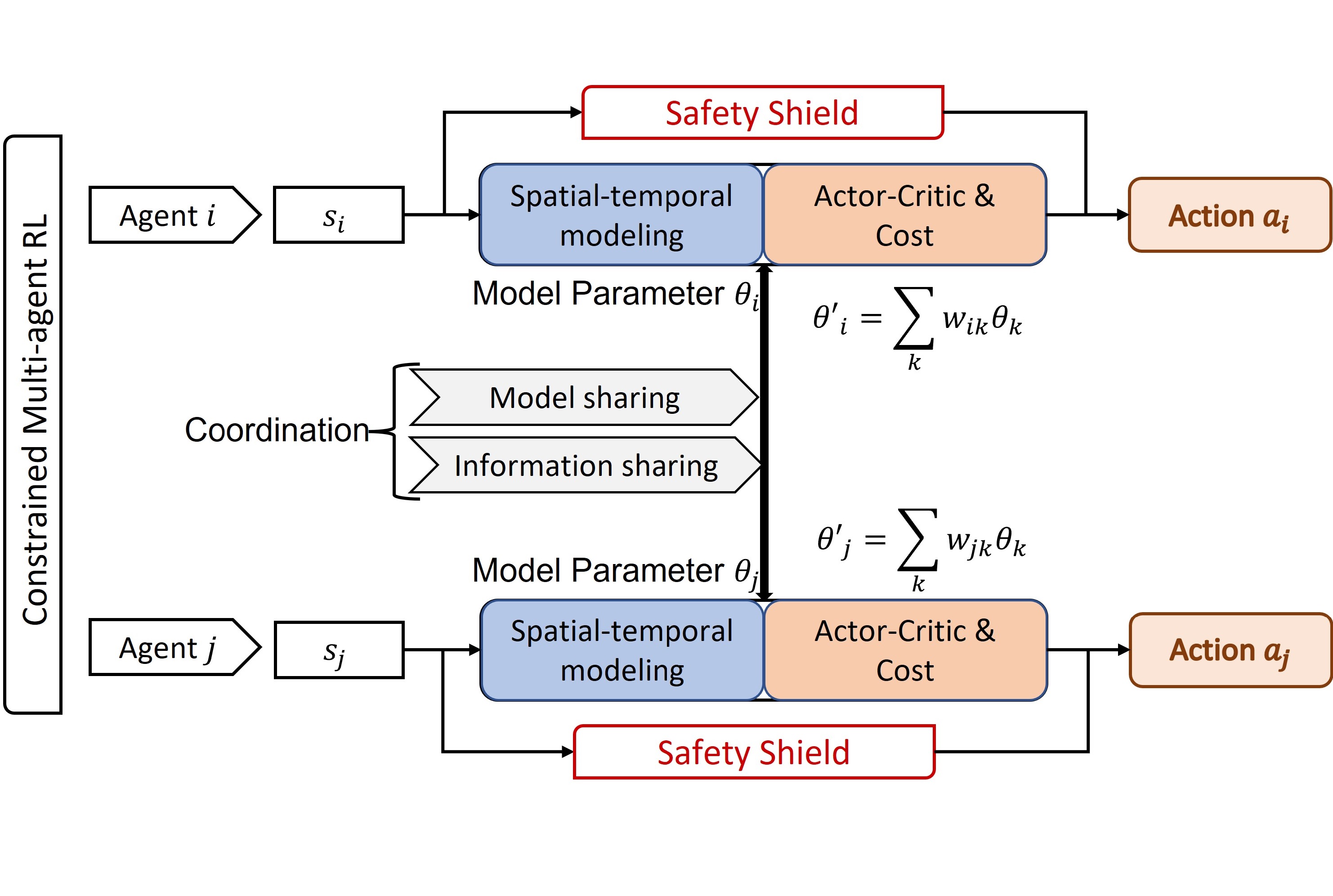


Communication technologies enable coordination among connected and autonomous vehicles (CAVs). However, it remains unclear how to utilize shared information to improve the safety and efficiency of the CAV system in dynamic and complicated driving scenarios. In this work, we propose a framework of constrained multi-agent reinforcement learning (MARL) with a parallel Safety Shield for CAVs in challenging driving scenarios that includes unconnected hazard vehicles. The coordination mechanisms of the proposed MARL include information sharing and cooperative policy learning, with Graph Convolutional Network (GCN)-Transformer as a spatial-temporal encoder that enhances the agent's environment awareness. The Safety Shield module with Control Barrier Functions (CBF)-based safety checking protects the agents from taking unsafe actions. We design a constrained multi-agent advantage actor-critic (CMAA2C) algorithm to train safe and cooperative policies for CAVs. With the experiment deployed in the CARLA simulator, we verify the performance of the safety checking, spatial-temporal encoder, and coordination mechanisms designed in our method by comparative experiments in several challenging scenarios with unconnected hazard vehicles. Results show that our proposed methodology significantly increases system safety and efficiency in challenging scenarios. Check out the [Paper] on arXiv.
Uncertainty Quantification of Collaborative Detection for Self-Driving
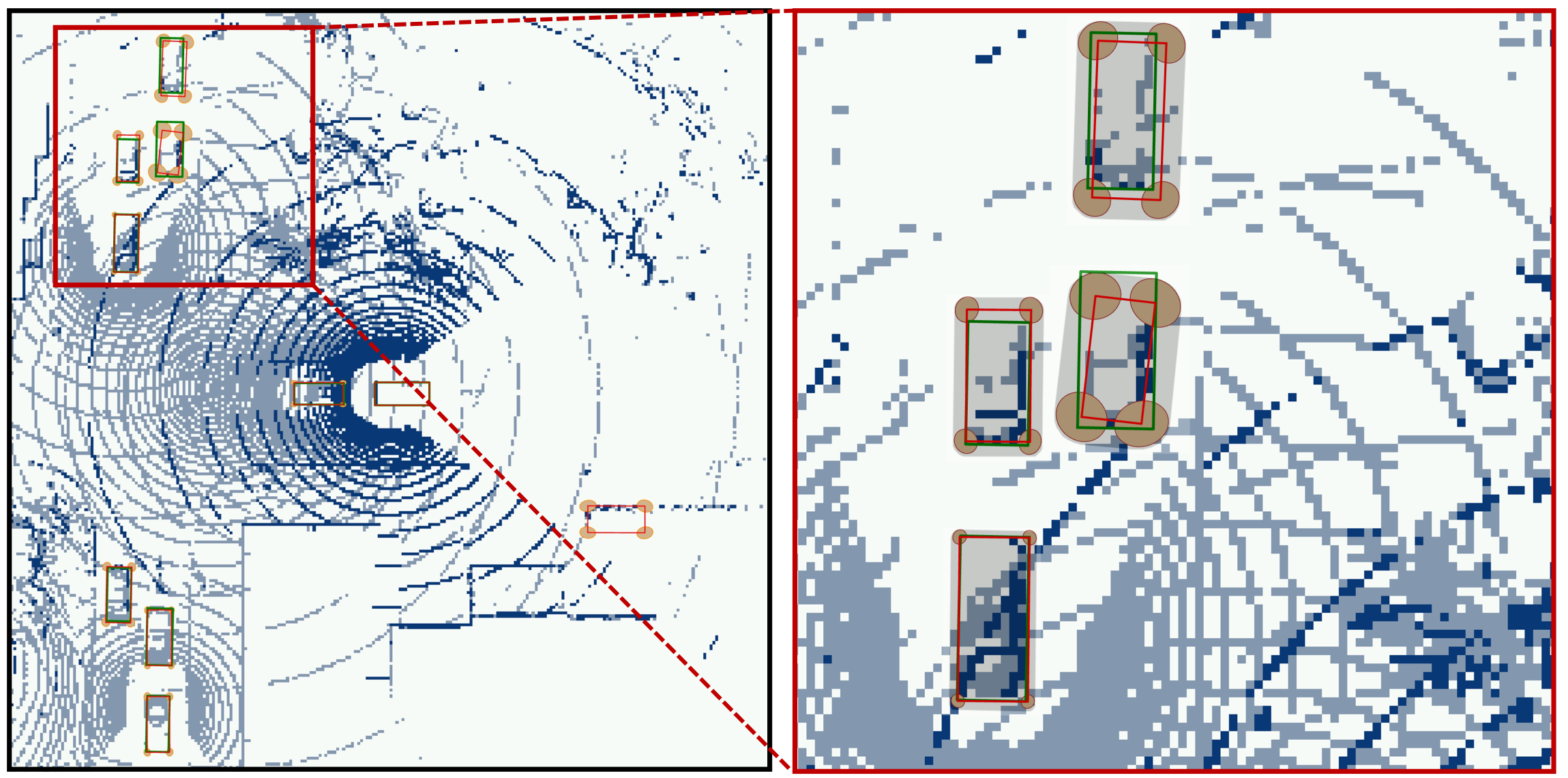
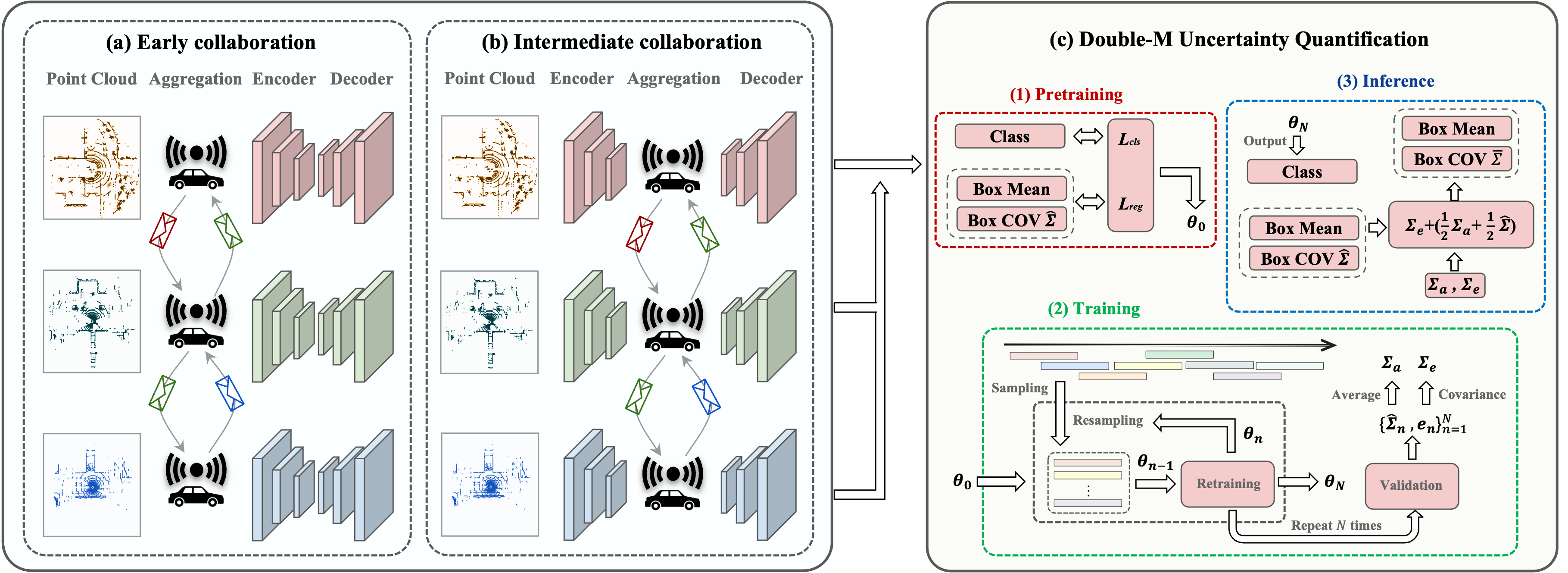
Sharing information between connected and autonomous vehicles (CAVs) fundamentally improves the performance of collaborative object detection for self-driving. However, CAVs still have uncertainties on object detection due to practical challenges, which will affect the later modules in self-driving such as planning and control. Hence, uncertainty quantification is crucial for safety-critical systems such as CAVs. Our work is the first to estimate the uncertainty of collaborative object detection. We propose a novel uncertainty quantification method, called Double-M Quantification, which tailors a moving block bootstrap (MBB) algorithm with direct modeling of the multivariant Gaussian distribution of each corner of the bounding box. Our method captures both the epistemic uncertainty and aleatoric uncertainty with one inference pass based on the offline Double-M training process. And it can be used with different collaborative object detectors. Through experiments on the comprehensive collaborative perception dataset, we show that our Double-M method achieves more than 4X improvement on uncertainty score and more than 3% accuracy improvement, compared with the state-of-the-art uncertainty quantification methods. Check out the [Paper] on arXiv.
Multi-Agent Reinforcement Learning for Safe and Efficient Behavior Planning
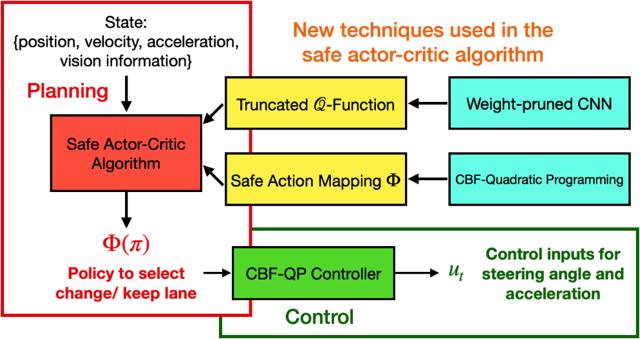
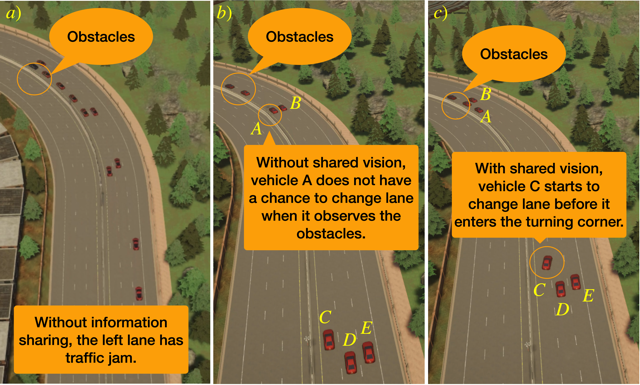
In this work, we design an information-sharing-based multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. The safe actor-critic algorithm we propose has two new techniques: the truncated Q-function and safe action mapping. The truncated Q-function utilizes the shared information from neighboring CAVs such that the joint state and action spaces of the Q-function do not grow in our algorithm for a large-scale CAV system. We prove the bound of the approximation error between the truncated-Q and global Q-functions. The safe action mapping provides a provable safety guarantee for both the training and execution based on control barrier functions. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams. Check out the [Paper] on arXiv and our website [website].
Stable and Efficient Shapley Value-Based Reward Reallocation for MARL
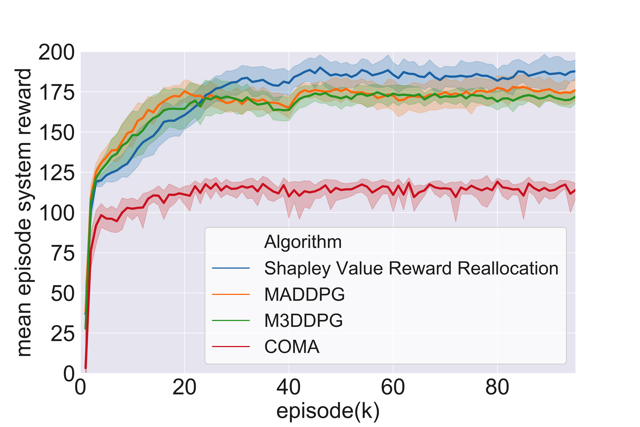
When each individual autonomous vehicle is originally self-interest, we can not assume that all agents would cooperate naturally during the training process. In this work, we propose to reallocate the system's total reward efficiently to motivate stable cooperation among autonomous vehicles. We formally define and quantify how to reallocate the system's total reward to each agent under the proposed transferable utility game, such that communication-based cooperation among multi-agents increases the system's total reward. We prove that Shapley value-based reward reallocation of MARL locates in the core if the transferable utility game is a convex game. Hence, the cooperation is stable and efficient and the agents should stay in the coalition or the cooperating group. We then propose a cooperative policy learning algorithm with Shapley value reward reallocation. In experiments, compared with several literature algorithms, we show the improvement of the mean episode system reward of CAV systems using our proposed algorithm. Check out the [Paper] on arXiv.